A CXO guide to what actually sits beneath dashboards, analytics, and AI
Most CXOs today can sense when their organization’s data foundation is fragile—even if they cannot articulate exactly why.
Dashboards take too long to update. Numbers differ across forums. Analytics initiatives feel harder than they should. New tools are added, yet decision confidence does not improve proportionally.
When this happens, the conversation often turns technical very quickly. Terms like “data lake,” “cloud migration,” “pipelines,” and “modern data stack” begin to dominate. For many senior leaders, this is where clarity drops and delegation increases.
The problem is not that the modern data stack is too complex. The problem is that it is rarely explained as a business system, rather than a collection of technologies.
This article explains the modern data stack in simple terms—not by listing tools, but by clarifying what problems each layer exists to solve and why confusion at this level creates downstream decision friction.
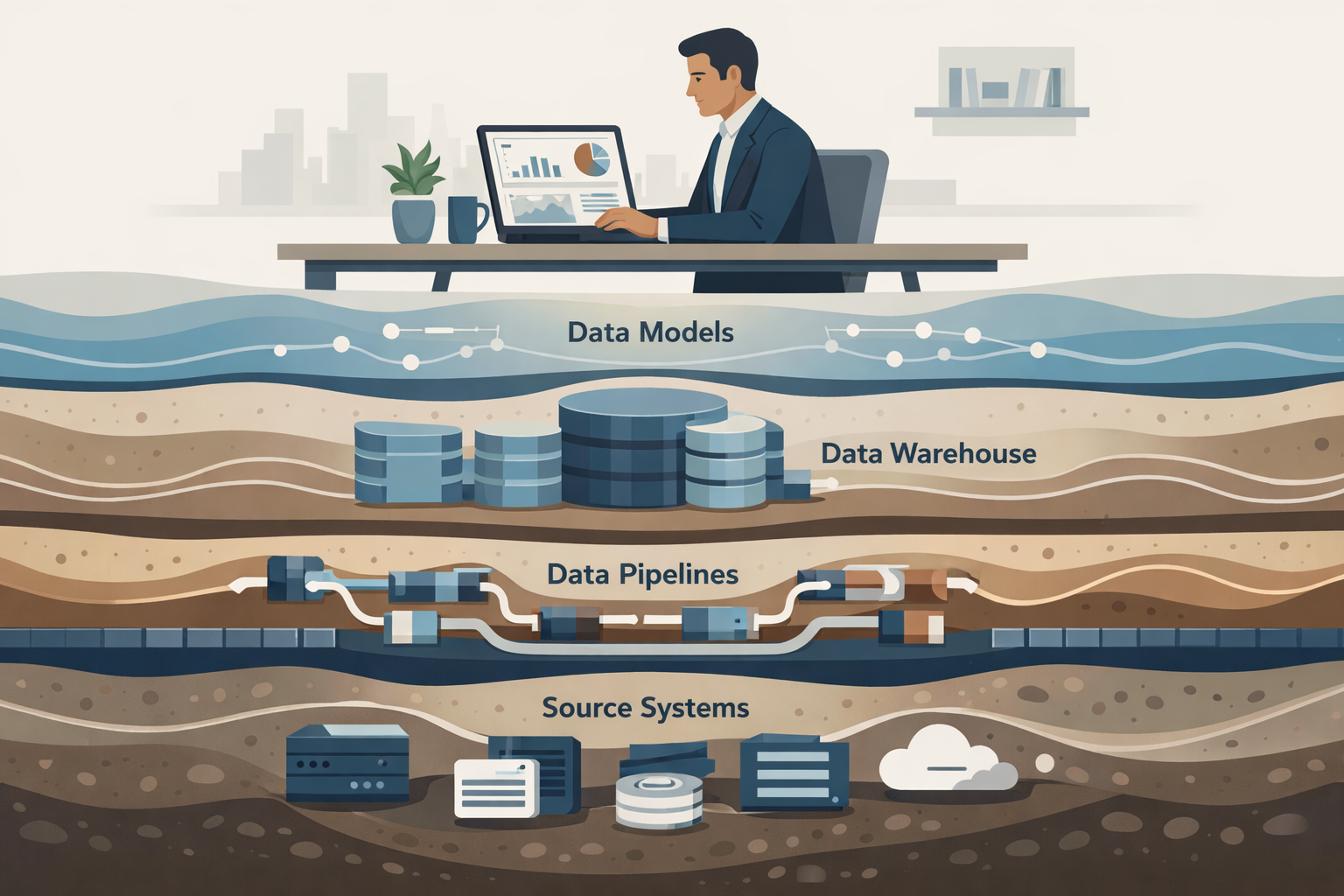
Why CXOs Should Care About the Data Stack at All
At a leadership level, the data stack is not an IT concern. It is the infrastructure through which information becomes decisions.
When the stack is well-designed, data flows quietly. Reports are trusted. Analytics feels natural. Leaders focus on trade-offs rather than explanations.
When it is poorly designed, friction shows up everywhere else: in finance reconciliations, in operational debates, in delayed decisions, and in repeated “data transformation” programs.
Understanding the stack is therefore not about learning technology. It is about understanding where value is created—or lost—between data and decisions.
What the “Modern Data Stack” Is Really Trying to Fix
Historically, data systems were built for record-keeping and transactions, not insight. ERP systems, CRMs, and operational platforms were designed to run the business, not to analyze it. Reporting was layered on afterward, often through manual extraction and spreadsheets. As organizations grew, this approach collapsed under its own weight.
The modern data stack emerged to solve three structural problems:
-
Data fragmentation across systems
-
Slow and brittle reporting processes
-
Inability to scale analytics beyond a few use cases
Seen this way, the stack is not a trend. It is an architectural response to complexity.
The Stack Explained as a Business Flow
Rather than thinking of the data stack as a technical architecture, it is more useful to think of it as a flow of accountability.
1. Source Systems: Where Reality Is Created
Every organization begins with operational systems—finance, sales, supply chain, manufacturing, and customer platforms. These systems record what happened.
At this level, data is transactional, fragmented, and context-specific. No strategic insight lives here yet. This is raw operational reality.
The key CXO insight: source systems are optimized for execution, not explanation. Expecting them to directly support analytics is the first design mistake many organizations make.
2. Data Ingestion & Pipelines: Where Reality Is Moved
The next layer exists to move data out of operational systems and into an analytical environment.
This is where data engineering begins to matter. Pipelines extract, transform, and load data so it can be analyzed reliably.
From a leadership perspective, this layer determines:
-
How fresh data is,
-
How consistent it becomes across systems, and
-
How fragile reporting is during change.
When pipelines are poorly designed, every downstream conversation suffers. Data arrives late. Numbers break unexpectedly. Teams lose trust.
This is why pipeline decisions are not technical preferences—they are operating-model decisions.
3. Central Data Layer: Where Data Becomes Shared
The modern stack introduces a central analytical layer—often called a data warehouse or data lakehouse—where data from across the organization comes together.
This layer exists to create a shared version of reality.
The distinction matters. Without a central layer, every function builds its own interpretation. With one, alignment becomes possible—but only if governance and modeling are disciplined.
Many organizations mistakenly believe that centralization alone creates trust. In reality, it only creates proximity. Trust must still be designed.
At this stage, many CXOs recognize the symptoms in their own organizations but are unsure where the breakdown actually occurs.
If your teams debate numbers more than decisions, or if reporting confidence varies by function, it may indicate structural issues within these foundational layers.
Contact us to discuss how your current data flow supports or constrains decision-making at the executive level.
4. Data Modeling Layer: Where Meaning Is Decided
This is the most underestimated layer of the stack.
Data models define how raw data is structured into business concepts—revenue, margin, customer, order, and inventory. They decide what is easy to analyze and what is hard.
For CXOs, this layer quietly determines:
-
Which KPIs feel intuitive?
-
Which questions can be answered quickly, and
-
Which debates repeat endlessly.
Poor modeling leads to KPI confusion. Good modeling makes insight feel obvious.
This is why data modeling is not a technical detail—it is a business translation layer.

5. Analytics & Consumption Layer: Where Decisions Are Influenced
Only at the top of the stack do dashboards, reports, and analytics appear.
This is the layer most visible to leadership—and the least powerful on its own.
When upstream layers are weak, this layer absorbs the pain. Dashboards multiply to compensate. Manual adjustments creep in. Explanations replace insight.
When upstream layers are strong, this layer becomes quiet. Fewer dashboards are needed. Decisions feel easier.
The key realization: most analytics problems originate below this layer, not within it.
Why the Stack Often Looks “Modern” but Feels Ineffective
Many organizations believe they have a modern data stack because they have adopted cloud platforms or new BI tools.
Yet effectiveness remains limited.
This happens because modernization is often interpreted as tool replacement, not flow redesign. Old habits are rebuilt on new platforms. Fragmentation persists—just faster.
From a CXO standpoint, this explains why technology refreshes fail to deliver expected returns. The architecture changed, but the operating logic did not.
What the Modern Data Stack Is Not
It is not:
-
A single product,
-
A fixed blueprint,
-
A guarantee of insight.
A modern data stack is a discipline, not a destination. It reflects deliberate choices about where data is standardized, where flexibility is allowed, and where accountability sits.
Organizations with modest stacks but strong discipline often outperform those with sophisticated stacks and weak foundations.
The Executive Lens That Actually Matters
For CXOs, the right questions are not:
-
“Do we have a modern stack?”
-
“Are we using the right tools?”
The better questions are
-
Where does data slow down today?
-
Where does trust break?
-
Where do teams rebuild the same logic repeatedly?
-
Which decisions feel harder than they should?
The answers to these questions reveal whether the stack is serving the business—or silently resisting it.
The Core Takeaway
The modern data stack exists to do one thing: reduce friction between data and decisions.
When it is designed as a business system, it fades into the background. When it is treated as a technology project, it becomes a constant source of effort and debate.
Understanding it at a conceptual level allows CXOs to guide conversations, challenge assumptions, and avoid over-engineering—without becoming technologists themselves.
That understanding is the foundation for every architectural and engineering decision that follows.
If your organization has invested heavily in data but still struggles with trust, speed, or decision confidence, the issue is rarely tooling—it is structure.
Schedule a call with us to review your data stack through an executive lens and identify where friction is being introduced—and how to remove it.
Get in touch with Dipak Singh: LinkedIn | Email
Frequently Asked Questions
1. Do CXOs need to understand the technical details of the data stack?
No. CXOs need to understand where accountability, trust, and decision friction are created. Technical depth can be delegated; architectural clarity cannot.
2. Is a modern data stack necessary for AI and advanced analytics?
Yes—but only if it is designed as a business system. AI amplifies existing data quality and modeling issues rather than fixing them.
3. Why do dashboards improve without improving decisions?
Because dashboards reflect the top of the stack. If upstream layers are fragmented or poorly modeled, visualization alone cannot create clarity.
4. How do we know which layer of the stack is causing problems?
Symptoms such as inconsistent KPIs, long reconciliation cycles, or repeated metric debates usually indicate issues in ingestion, modeling, or governance—not BI tools.
5. Can smaller organizations benefit from modern data stack principles?
Absolutely. Discipline matters more than scale. Clear modeling and ownership often outperform complex architectures with weak foundations.






